Key Takeaways
- The computers have largely disagreed with the human polls and with each other. The Harris Poll differed from the collective computer ranking by an average of 3.40. The Coach’s Poll differed by 3.59.
- In general, the human polls bested the computer systems.
The Predictive Power of Humans vs. Computers
There are three equally weighted components of the BCS rankings. Two of them are human polls, the Harris Poll and the USA Today Coach’s poll. The last is (loosely) an average of the following six computer ranking systems: Peter Wolfe (PW), Colley Matrix (CM), Jeff Sagarin (JS), Richard Billingsley (RB), Kenneth Massey (KM), and Anderson and Hester (A&H).
Before we consider the predictive power of each component, let us see to what extent the components agree. If two components largely agree, then they will have nearly equal predictive power. This is the case for the two human polls. For each team in the BCS top 25 in each of the 8 weeks in a given season, we took the absolute value of the difference in their Harris Poll ranking and their Coach’s Poll ranking. The average difference over the last three seasons was .65. On average, the two human polls rank teams to within a half ranking of each other. (As we did in the first section, any team not ranked by a respective poll was entered as being ranked 26th overall.)
Since the two human polls agree, there is no opportunity for them to have differing predictive power. In contrast, the computers have largely disagreed with the human polls and with each other. The Harris Poll differed from the collective computer ranking by an average of 3.40. The Coach’s Poll differed by 3.59.
Table 4 provides the average difference between each of the six computer rankings and the Coach’s Poll (labeled Coach). It then presents the difference between each individual computer ranking and the average computer ranking (labeled Comp). The Table shows that all of the computer systems disagree with the coach’s poll. The largest difference is with Sagarin’s system. Sagarin and the Coach’s Poll differed (on average) by almost five spots in the rankings.
Table 4: Average Difference in Rankings for 2010-2012 BCS Top 25 Teams
| Average | Average | ||
| A&H – Coach | 3.63 | A&H – Comp | 1.63 |
| RB – Coach | 3.00 | RB – Comp | 2.95 |
| CM – Coach | 3.49 | CM – Comp | 2.04 |
| KM – Coach | 4.60 | KM – Comp | 1.85 |
| JS – Coach | 4.83 | JS – Comp | 2.51 |
| PW – Coach | 3.56 | PW – Comp | 1.36 |
The computer rankings have not agreed with the human polls. The difference has been particularly great at the initial rankings. Chart 5 shows the average difference by week during the 2010-2012 seasons.
Chart 5: Average difference by week in the Human and Computer Polls
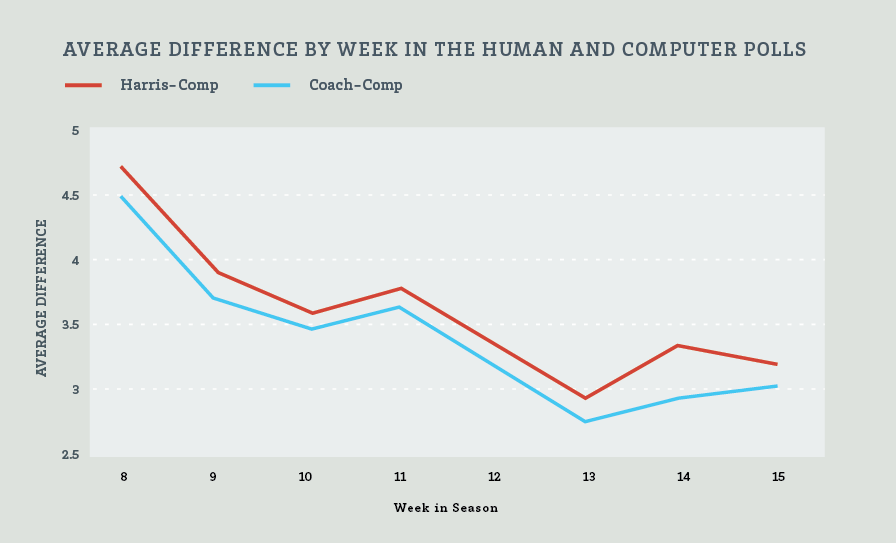
The significant difference in rankings between the human and computer polls presents the opportunity of one’s initial rankings to be a far better predictor of final BCS rankings than the others. Table 6 measures how good of a predictor the initial rankings in each of the two human polls, the six computer systems, and the computer average were of final BCS rankings. Here, we looked only at teams that were in the BCS top 25 initially. Teams that dropped out of the top 25 in the final standing were given a rank of 26 for that week. In general, the human polls bested the computer systems. The only exception was the 2011 initial Anderson and Hester computer rankings. That year, A & H was the best predictor of the group. Interestingly, in the following season (2012), the initial A & H rankings were the worst.
Table 6: Average Movement from Initial Rankings to Final BCS Rankings
| 2010 | 2011 | 2012 | 3 year avg | |
| Harris | 5.32 | 4.40 | 5.08 | 4.93 |
| Coach’s | 5.36 | 4.24 | 5.36 | 4.99 |
| Comp Avg. | 6.72 | 4.20 | 6.56 | 5.83 |
| A&H | 7.36 | 4.16 | 7.48 | 6.33 |
| RB | 7.76 | 4.56 | 6.24 | 6.19 |
| CM | 6.76 | 4.80 | 6.60 | 6.05 |
| KM | 7.56 | 5.76 | 6.52 | 6.61 |
| JS | 6.12 | 5.72 | 5.76 | 5.87 |
| PW | 6.28 | 4.88 | 6.84 | 6.00 |
Win AD equips your athletic department with better tools to predict your own financial performance with easy benchmarking—customizable comparisons of revenue and expense trends between institutions. Get a 4-year view of NCAA financials in the same place you compare wins/losses, post-season performance, APR, and RPI for every sport—from football to fencing. Win AD is a better way to manage resources and maximize performance.
Contact us for a free demo of Win AD